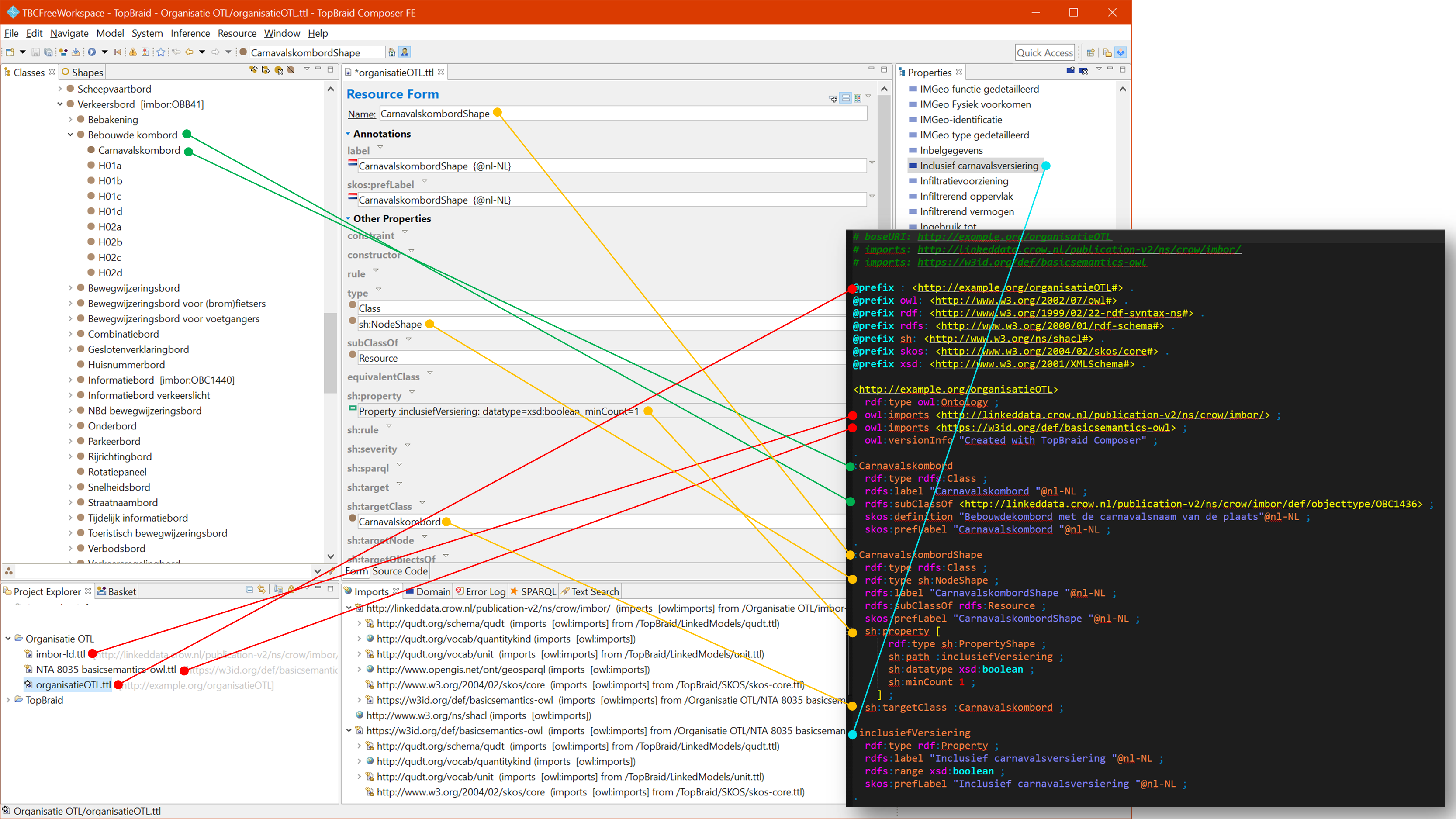
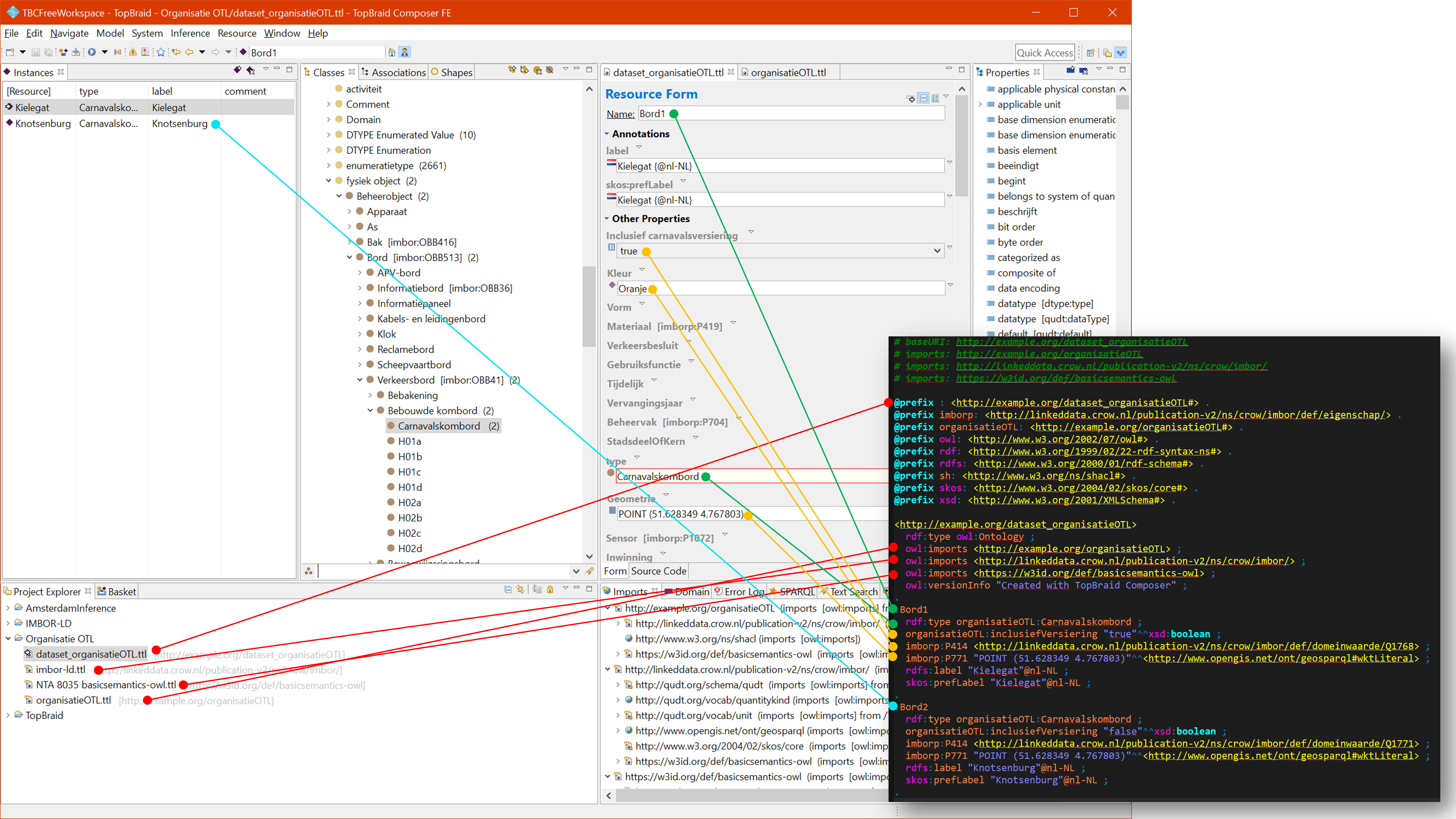
Gebruik van CSV bestanden in Excel
IMBOR-LD is in het openstandaard CSV spreadsheet formaat beschikbaar. Omdat dit in essentie een tekst bestand is, is er een extra stap nodig om dit in bijvoorbeeld Microsoft Excel netjes te krijgen. De minimale stappen hiervoor worden door de VNG goed omschreven op deze website:
CSV in Excel
### Inhoud spreadsheet
In de spreadsheets staan verschillende kolommen. Hieronder een uitleg per kolom. De schuin gedrukte representeren de koppelvlakken tussen respectievelijk A & B en B & C.
| Spreadsheet | Kolom | Uitleg |
|------------- |-------------------------- |--------------------------------------------------------------------- |
| A | FysiekObjectURI | Unieke identifier van het ObjectType |
| | FysiekObjectLabel | Naam van het ObjectType |
| | _EigenschapURI_ | Unieke identifier van de eigenschap |
| | EigenschapLabel | Naam van de eigenschap |
| | EigenschapVanObjectLabel | Naam het ObjectType waar de eigenschap van overgeërfd is |
| | Versie | Versie van IMBOR waar de regel komt |
| B | _EigenschapURI_ | Unieke identifier van de eigenschap |
| | EigenschapLabel | Naam van de eigenschap |
| | _VastewaardeLijstURI_ | Unieke identifier van de corresponderende vastewaardelijst (i.v.t.) |
| | VastewaardelijstLabel | Naam van corresponderende vastewaardelijst (i.v.t.) |
| | Datatype | Hoe de eigenschap waardemoet worden genoteerd (i.v.t.) |
| | Eenheid | In welke maat de eigenschap waarde moet worden genoteerd (i.v.t.) |
| | Grootheid | Welke betekenis de waarde van de eenheid heeft (i.v.t.) |
| | MaximaalAantalVoorkomen | Hoe vaak de eigenschap mag voorkomen per ObjectType |
| | Versie | Versie van IMBOR waar de regel uit komt |
| C | _VastewaardeLijstURI_ | Unieke identifier van de corresponderende vastewaardelijst |
| | VastewaardelijstLabel | Naam van corresponderende vastewaardelijst |
| | VastewaardeURI | Unieke identifier van de waarde in de waardelijst |
| | VastewaardeLabel | Naam van de waarde in de waardelijst |
| | Versie | Versie van IMBOR waar de regel uit komt |
### Objecten in scope
Er wordt begonnen met het selecteren van de juiste ObjectTypen in spreadsheet A. Niet allen zullen van belang zijn in een organisatie of binnen een project. Degene die niet van belang zijn, kunnen middels het verwijderen van de juiste rijen (op basis van de 2e kolom) er uit gehaald worden.
Wanneer er een ObjectType niet in IMBOR staat kan er uiteraard een toevoeging worden gemaakt met dezelfde opzet met een 'nieuw' objecttype. In dit geval is het aan te raden om de regels van ongeveer een zelfde ding te pakken, deze onderaan te plakken en deze te modificeren waar nodig. De kolommen met 'URI' er in moeten vervolgens uniek gemaakt worden. Best practice zou zijn: ```="organisatie afkorting"&"-"&"type"&"volgnummer"```. Bijvoorbeeld: